
 A scanned PDF document is a digital file containing an image of a physical document scanned using a scanner. The scanner captures the text and images on the physical document and converts them into a digital format, then saves them as a PDF file. Scanned PDF documents may contain any type of printed material, including books, reports, invoices, and other documents. Unlike editable PDF documents, scanned PDFs are typically not searchable or editable without using optical character recognition (OCR) software.
A scanned PDF document is a digital file containing an image of a physical document scanned using a scanner. The scanner captures the text and images on the physical document and converts them into a digital format, then saves them as a PDF file. Scanned PDF documents may contain any type of printed material, including books, reports, invoices, and other documents. Unlike editable PDF documents, scanned PDFs are typically not searchable or editable without using optical character recognition (OCR) software.
Benefits of the Searchable PDF File
Some benefits of searchable PDF documents include the following:
- Increased productivity: Searching for specific information in a searchable PDF document is much faster and more efficient than manually scanning through pages of text.
- Improved accessibility: Screen readers can read searchable PDF documents aloud, making them accessible to visually impaired individuals.
- Easier collaboration: Collaborating on documents is made more accessible when text is searchable. Team members can quickly find and extract the necessary information to complete their work.
- Reduced storage space: Searchable PDF documents can be compressed without losing their searchability, allowing them to take up less storage space.
OCR (Optical Character Recognition) technology helps to generate searchable PDF documents. It is a software tool that digitizes large volumes of documents, converts physical records into searchable electronic files, and improves data entry accuracy. OCR software can be standalone, embedded in a scanner, or integrated into document management software. However, OCR accuracy can be impacted by document quality, font type, and language, so choosing high-quality OCR software and optimizing the scanning process for the best results is crucial.
What is OCR?
OCR, known as Optical Character Recognition, is a technology that allows the recognition of printed or handwritten text within an image and then converts that text into machine-readable text.
The four main types of OCR are:
- Optical Character Recognition, or OCR, is a technology used to recognize printed text within an image and convert it into machine-readable text. OCR technology is widely used for digitizing printed documents, such as books, magazines, and legal documents.
- OWR, or Optical Word Recognition, is a technology similar to OCR but specifically designed to recognize entire words within an image. This technology is commonly used in handwriting recognition applications, where it is essential to recognize complete words rather than individual characters.
- OMR, or Optical Mark Recognition, is a technology used to recognize specific marks made on a paper form, such as checkboxes or bubbles. OMR technology is commonly used in standardized tests, surveys, and other applications where data needs to be collected from paper forms.
- ICR, or Intelligent Character Recognition, is a technology that recognizes handwritten text within an image. ICR technology is more complex than OCR or OWR because it requires identifying individual characters and matching those characters against a database of known characters.
When comparing these technologies, it is vital to consider their strengths and weaknesses.
- OCR is highly accurate for recognizing printed text but may struggle with handwriting or poorly printed text.
- OWR is designed explicitly for handwriting recognition and can be more accurate for that application.
- OMR is highly accurate for recognizing specific marks on a paper form but cannot recognize text.
- ICR is the most complex and can handle a broader range of handwriting, but it may require extensive training and may not be accurate enough for some applications.
Ultimately, the choice of technology depends on the specific application and the type of text or symbols that need to be recognized.
Comparison of Popular OCR Software Available in 2023
As discussed earlier, OCR technology is mainly used for the task of automatically extracting text from scanned PDFs and images. There are plenty of tools available for this purpose, and here, we will provide a brief introduction to the most popular OCR software in 2023:
- AcePDF
- Tesseract OCR
- ABBYY FineReader
- Google Cloud Vision
- Amazon Textract
All of these tools come with a different set of features and we have asses their strengths and weaknesses to make it easy for you to choose the best OCR tool that can best fit your purposes. In our comparison, we have found that AcePDF is easy to use and offers a range of OCR-related features, which will make the task of PDF text recognition a no-brainer for you. It doesn’t have any problem with the well-scanned documents and even recognized the text in the smartphone-captured document similarly well.
OCR a Scanned PDF Document
Most PDFs floating around the web contain text incorporated in them, and many popular desktop and mobile programs and scanner software bundles have OCR technology built in. Nonetheless, there are still cases where the source document or image has significant quantities of non-embedded text that cannot be extracted mechanically.
In this scenario, OCR can be performed automatically with the help of a pipeline of free and open-source software. This is especially helpful when working with an extensive corpus of documents that need to have their whole text indexed or when ingesting documents or images to a web application that needs to extract text.
Here is a step-by-step guide to OCR a scanned PDF document:
- Choose an OCR software: Several OCR software are available in the market. You can choose any of them, such as AcePDF or any other you are comfortable using.
- Open the scanned PDF document: Open the PDF document you want to OCR in your OCR software.
- Select the OCR functionality: Start the OCR process by selecting the OCR tool in your OCR software. The location of the OCR tool may vary depending on the software you are using.
- Select OCR settings: Choose the document's language that you want to OCR. You may also have the option to select the OCR accuracy level, which may affect the processing time and output quality.
- Start the OCR process: Once you have selected the OCR settings, start the OCR process by clicking the "OCR" button. It may take some time, depending on the size of the document and the accuracy level you have selected.
- Review OCR output: After the OCR process is complete, review the OCR output to ensure the text is accurately recognized. Check for any errors, misspellings, or formatting issues.
- Save the OCR output: Once satisfied with the OCR output, save the document with the OCR output as a new PDF file. You may also be able to save the document in other formats, such as Microsoft Word or plain text.
- Edit the OCR output (Optional): If there are any errors in the OCR output, you can edit the text in your OCR software or export the text to a word processor to make any necessary changes.
Following these steps, you can OCR a scanned PDF document and convert it into a searchable and editable digital format.
Best OCR Software
If you're new to optical character recognition (OCR), AcePDF is the only tool you need. Performing OCR to make scanned PDFs searchable is just one of the many features that AcePDF can help you with. As a robust PDF editor and converter, it comes with many unique tools that will assist you in managing your PDF workflows and ultimately help you be more productive at work. Some of these amazing features are as follows:
- Annotations and markup features abound in this PDF editor, which allows the annotation of PDF documents with highlights, underlines, callouts, arrows, and much more.
- Effortlessly convert PDFs to editable formats like Word, Excel, or PowerPoint using this PDF editor's in-built converter.
- Headers and footers feature to improve the readability of the PDF document as a whole.
Common OCR Issues and Solutions
OCR technology can be beneficial in recognizing text within images, but several common issues can arise during the OCR process. Here are some of the most common OCR issues and how AcePDF can help solve them:
- Poor Image Quality: If the image being OCR-ed is of poor quality, the OCR software may not accurately recognize the text. AcePDF uses advanced image processing algorithms to enhance image quality and improve OCR accuracy.
- Mixed Languages: If the image contains text in multiple languages, the OCR software may have difficulty recognizing the text. AcePDF supports OCR for over 20 languages, making it easy to acknowledge accurately mixed-language text.
- Complex Layouts: The OCR software may have difficulty accurately recognizing the text if the image contains complex layouts, such as multiple columns or tables. AcePDF's advanced OCR algorithms are designed to accurately identify text within complex layouts, making it easy to extract data from such documents.
- Large Documents: If the image being OCR-ed is large, it can take a long time to complete the OCR process. AcePDF uses advanced parallel processing algorithms to OCR large documents quickly and efficiently.
Make Scanned PDF File Searchable
A searchable PDF is a document that allows the user to search for specific text or keywords within the document.
AcePDF may be used to make scanned PDF files searchable; here's how:
Step 1 Install AcePDF and Launch it
Launch AcePDF and load the scanned PDF file you want to make searchable. Once the scanned PDF document is open in AcePDF, go to the main menu and choose the OCR tool. In most cases, you may find the OCR function under the "Tools" section located on the left side of the program.Try it for Free
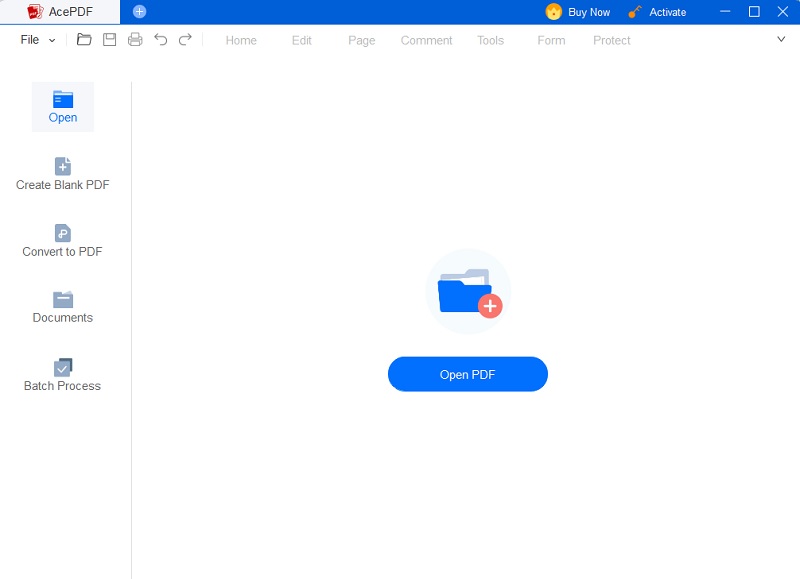
Step 2 Choose OCR Language and Settings in the OCR Tool Dialog Box
Choose OCR options like page range and output format. Choose the language of the scanned document to match the one supported by AcePDF's optical character recognition (OCR).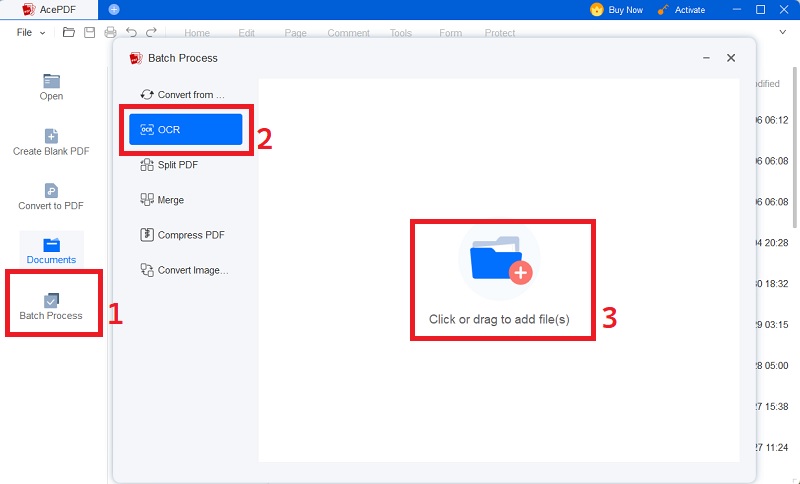
Step 3 Begin the OCR Process
To begin the OCR process, click the “OK” button. After that, AcePDF will examine the file and determine how to pull the text from the image. Once OCR has been completed, inspect the output to make sure the text was correctly recognized. Verify that it is free of typos, grammatical mistakes, and poor presentation. You can correct any mistakes in the text by editing it in AcePDF.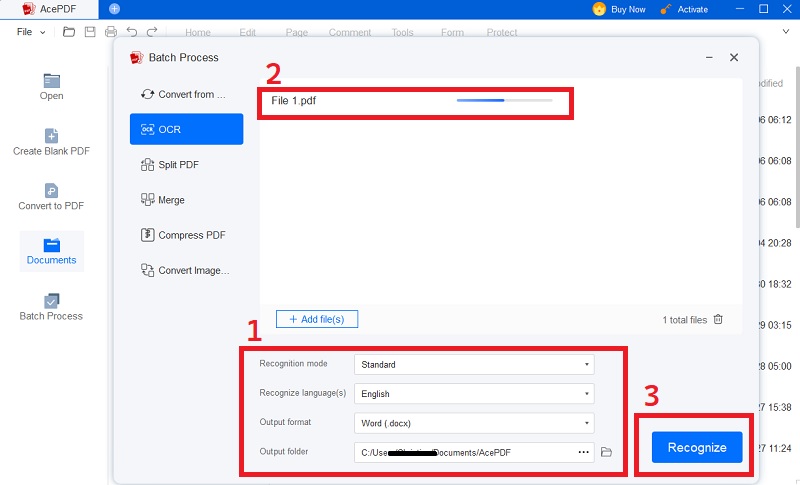
Step 4 Save the File
Save the Searchable PDF File Once you achieve the desired results, save the document as a searchable PDF file.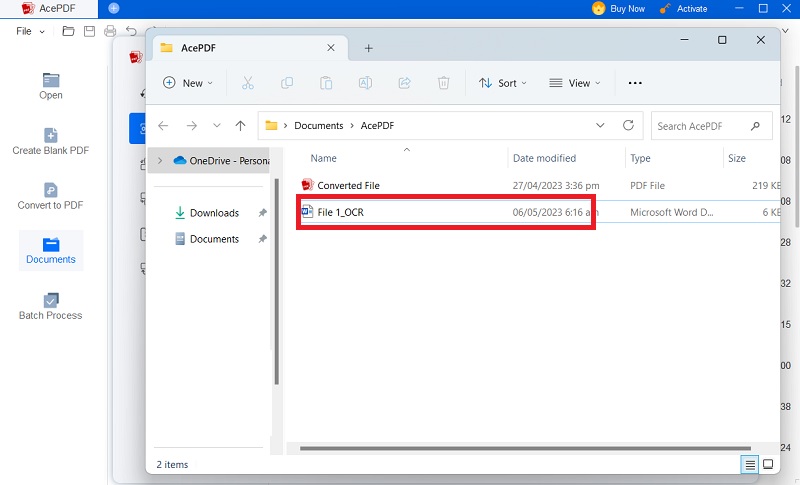
Tips for Searching Scanned PDFs
It wouldn’t be wrong to say that PDF is currently one of the most commonly used document formats. At times, you might need to run the text recognition to make the content on this page searchable and selectable. However, manually searching for a specific phrase or word in a PDF that has hundreds of pages can be challenging. If you’re one of those thousands of users who frequently use PDFs, then here we will help you to know how to search scanned PDF documents and discuss some tips for creating scanned PDFs searchable.
How to Search Text in a Scanned PDF Document?
In this section, you will find the steps that you can take to search for a scanned PDF:
- First of all, you need to convert the scanned PDF into an editable format, such as a Word document. For that purpose, you can use a PDF converter such as AcePDF.
- Download the document in this editable text format, and then, you will be able to edit, customize the pages and change the language if you want.
- In the final step, you can now search for your specific text. You can simply press the ‘Ctrl + F' keys and enter the word or phrase that you are looking to search for into the search bar.
Best Practices for Making Scanned PDF Documents Searchable
After discussing how to search for text in a scanned PDF document, here we are going to share some of the best practices that will help you maximize the searchability and benefits of using PDF documents.
- Always make sure to get the right resolution, when scanning images to PDF. As OCR quality can also suffer from lower scan resolution, so it is recommended to scan at 300 dpi (dots per inch).
- You should opt for grayscale over B&W because it will help to keep more details. In case your document has colored images or charts, then you should make sure to scan it in color mode.
- All OCR programs aren’t created equal, and the quality of OCR for making scanned PDFs searchable will based upon the settings and features offered by the software. So, it is necessary to get a right software that can deliver better quality OCR.
- Too high or low brightness can negatively affect accuracy and searchability of PDF documents. Therefore, a medium brightness of 50% would be a safe option for most of the scans.
- Usually, scanners have plenty of settings that can help to improve scan quality and ultimately the searchability. For instance, ‘background removal’ and ‘edge shadow removal’ can improve the readability of the documents. However, they impair OCR accuracy at times. So, you should run some tests and watch which settings can help to make your documents searchable.
Frequently Asked Questions
A. Do All PDF Files Have the Same Structure?
- Absolutely not! There are many different ways to make a PDF. PDFs generated electronically and from scanned paper documents are the two most prevalent types you'll encounter. This produces a "native" PDF and scanned pdfs, respectively. PDF interactivity depends on how the document was originally prepared.

B. Can You Explain Native PDF?
- "Native" PDFs are developed digitally from another digital source. A native PDF is created from another digital format, such as Microsoft Word or Excel. Native PDF files contain a readable and interpretable internal structure.
C. How Can I know if I have a searchable PDF?
- To know whether your PDF file is searchable, you will need to make sure that the particular file is text-based. This means that it has to contain real text. For checking if you have a searchable PDF file or not, you have to open it and search or select some text with your keyboard or mouse. If you aren’t able to select or highlight text, it simply means that the PDF isn’t searchable.
